URL到页面加载过程
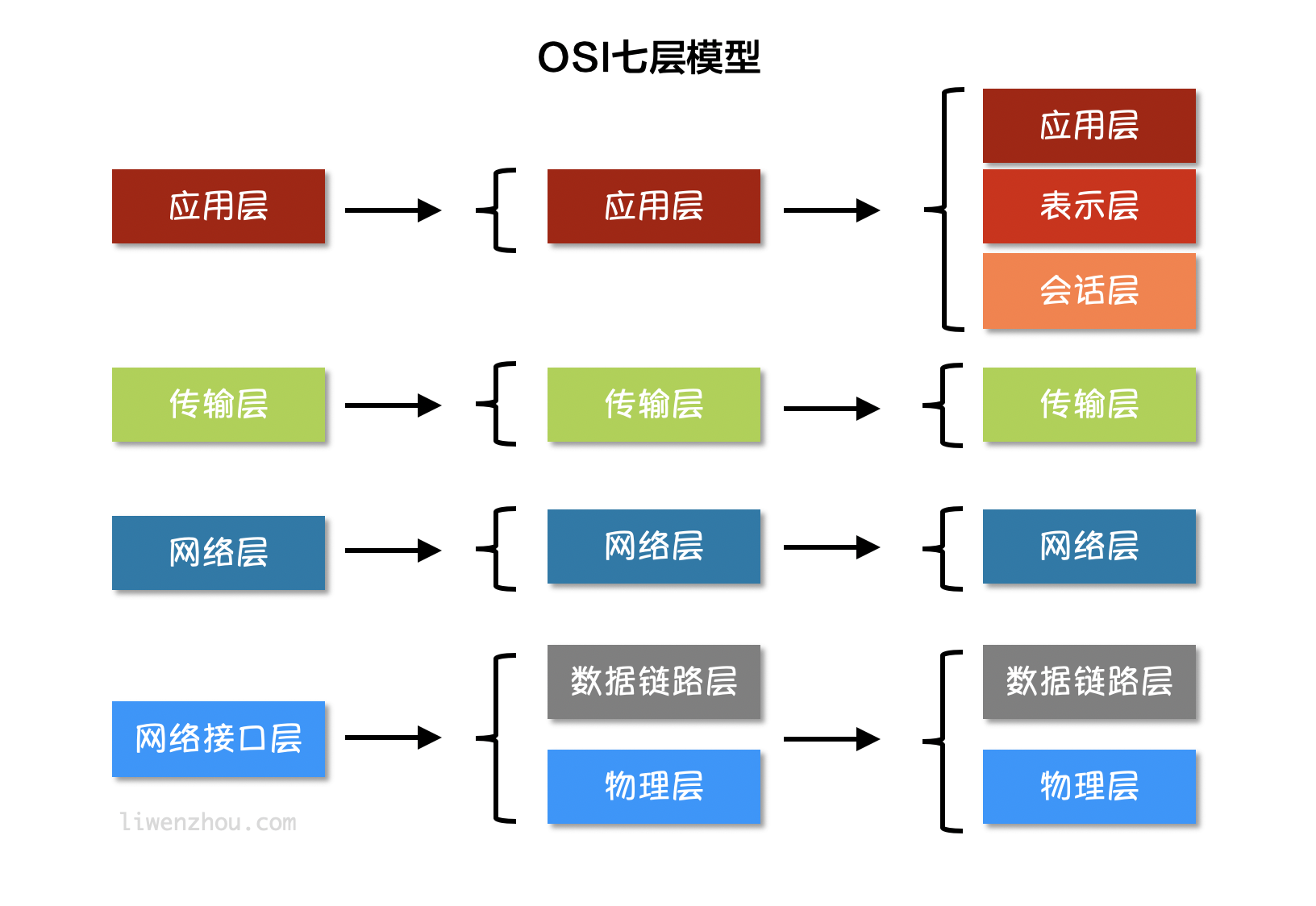
# OIS 七层模型模型
原文:https://www.liwenzhou.com/posts/Go/15_socket/
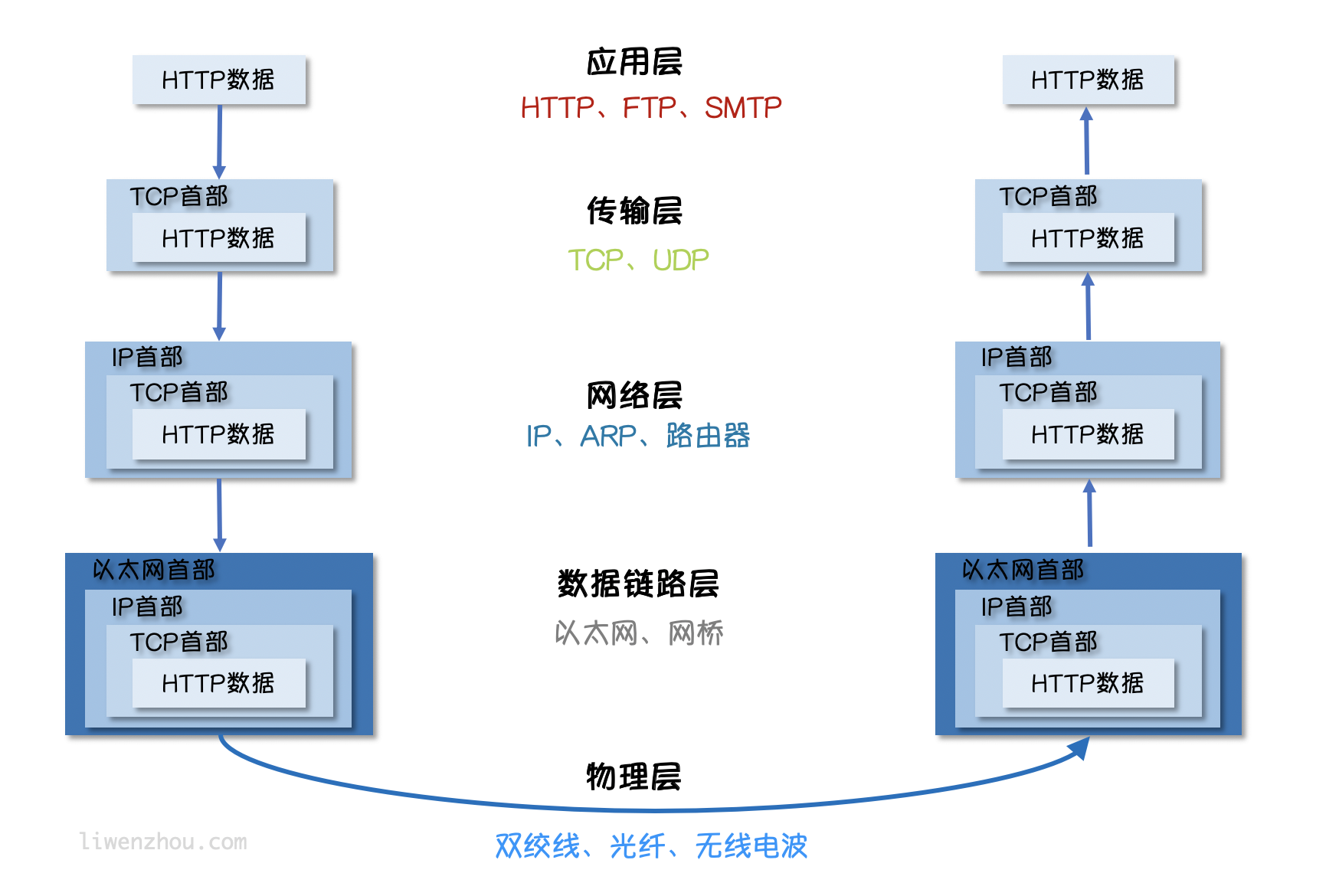
# 五层模型
原文:https://www.liwenzhou.com/posts/Go/15_socket/
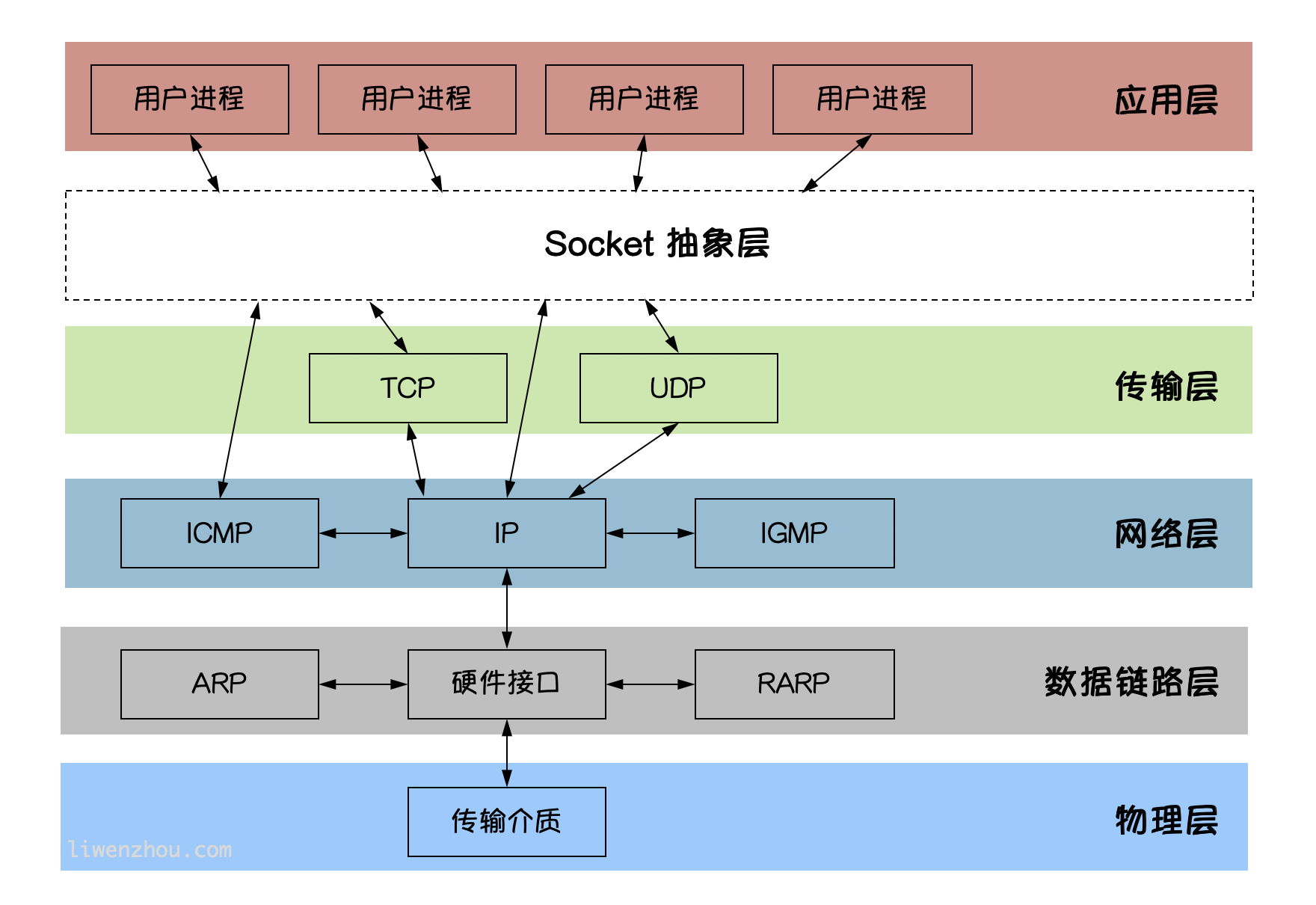
# socket图解
原文:https://www.liwenzhou.com/posts/Go/15_socket/
# TCP
原文:https://www.cnblogs.com/xiaolincoding/p/12638546.html
- TCP 是面向连接的、可靠的、基于字节流的传输层通信协议
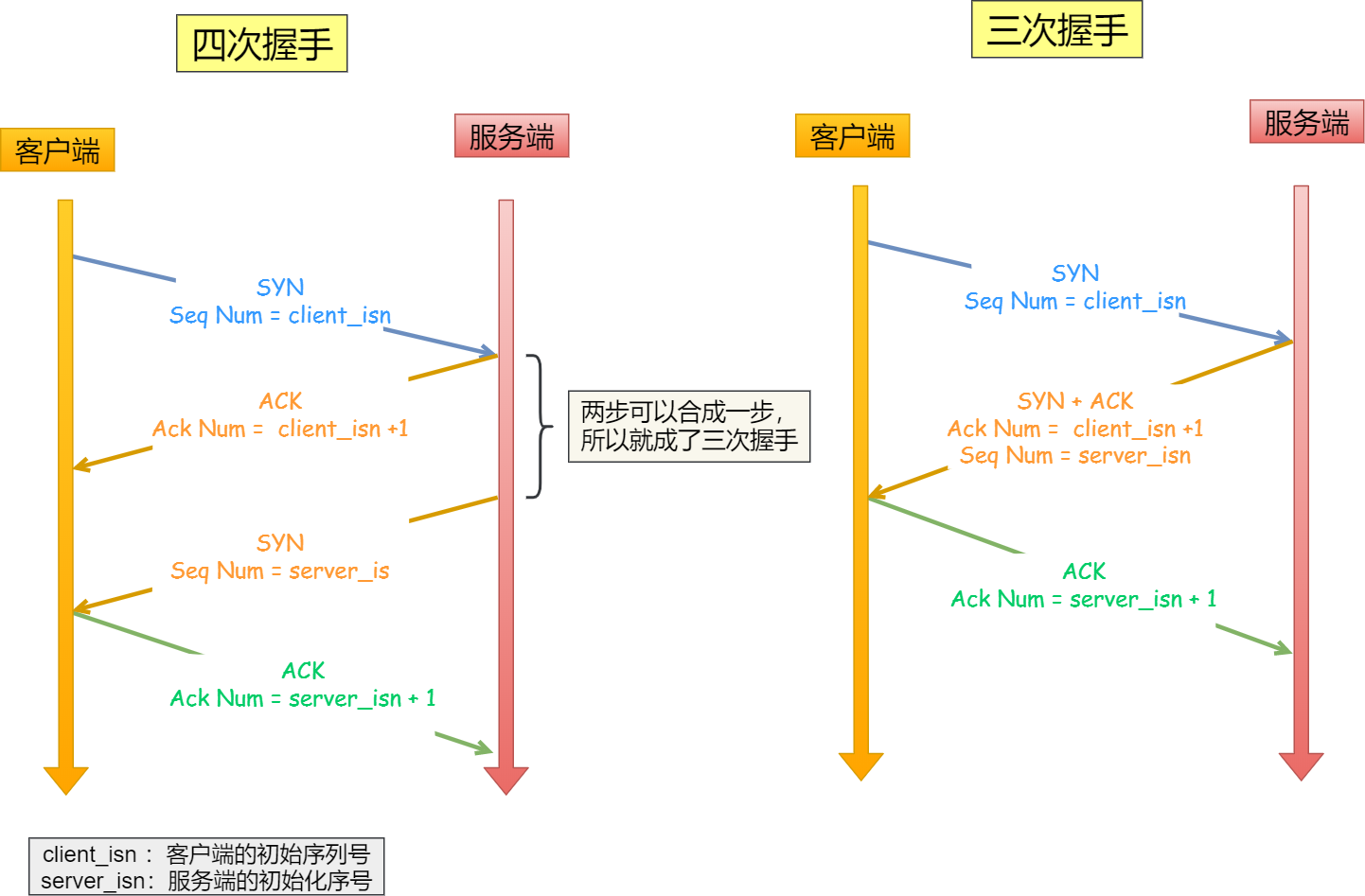
SYN: Synchronize 同步
ACK: Acknowledge 确认
Seq: Sequence 序号
三次握手 https://zhuanlan.zhihu.com/p/388704023 (opens new window)
- 第一次握手(SYN=1, seq=x),发送完毕后,客户端进入 SYN_SEND 状态
- 第二次握手(SYN=1, ACK=1, seq=y, ACKnum=x+1), 发送完毕后,服务器端进入 SYN_RCVD 状态
- 第三次握手(ACK=1,ACKnum=y+1),发送完毕后,客户端进入 ESTABLISHED 状态,当服务器端接收到这个包时,也进入 ESTABLISHED 状态,TCP 握手,即可以开始数据传输
四次挥手 https://zhuanlan.zhihu.com/p/388704023 (opens new window)
- 第一次挥手(FIN=1,seq=u),发送完毕后,客户端进入FIN_WAIT_1 状态
- 第二次挥手(ACK=1,ack=u+1,seq =v),发送完毕后,服务器端进入CLOSE_WAIT 状态,客户端接收到这个确认包之后,进入 FIN_WAIT_2 状态
- 第三次挥手(FIN=1,ACK1,seq=w,ack=u+1),发送完毕后,服务器端进入LAST_ACK 状态,等待来自客户端的最后一个ACK
- 第四次挥手(ACK=1,seq=u+1,ack=w+1),客户端接收到来自服务器端的关闭请求,发送一个确认包,并进入 TIME_WAIT状态,等待了某个固定时间(两个最大段生命周期,2MSL,2 Maximum Segment Lifetime)之后,没有收到服务器端的 ACK ,认为服务器端已经正常关闭连接,于是自己也关闭连接,进入 CLOSED 状态。服务器端接收到这个确认包之后,关闭连接,进入 CLOSED 状态
为什么挥手需要四次?
- 关闭连接时,客户端向服务端发送 FIN 时,仅仅表示客户端不再发送数据了但是还能接收数据;
- 服务器收到客户端的 FIN 报文时,先回一个 ACK 应答报文,而服务端可能还有数据需要处理和发送,等服务端不再发送数据时,才发送 FIN 报文给客户端来表示同意现在关闭连接。
# TCP和UDP的区别
https://juejin.cn/post/6908327746473033741#heading-75
| UDP | TCP | |
|---|---|---|
| 是否连接 | 无连接 | 面向连接 |
| 是否可靠 | 不可靠传输 | 可靠传输 |
| 连接对象个数 | 支持一对一,一对多,多对一和多对多交互通信 | 只能是一对一通信 |
| 传输方式 | 面向报文 | 面向字节流 |
| 首部开销 | 首部开销小,仅8字节 | 首部最小20字节,最大60字节 |
# 从输入 URL 到页面加载的过程
1.从浏览器接收 url 到开启网络请求线程 (浏览器的机制以及进程与线程之间的关系)2.开启网络线程到发出一个完整的 http 请求 (涉及到 dns 查询,tcp/ip 请求,五层因特网协议栈等知识,tcp三次握手,四次挥手)3.从服务器接收到请求到对应后台接收到请求 (涉及到负载均衡,安全拦截以及后台内部的处理等)4.后台和前台的 http 交互 (这一部分包括 http 头部、响应码、报文结构、cookie 等知识,可以提下静态资源的 cookie 优化,以及编码解码,如 gzip 压缩等)5.单独拎出来的缓存问题,http 的缓存 (这部分包括 http 缓存头部,etag,catch-control 等)6.浏览器接收到 http 数据包后的解析流程 (解析 html-词法分析然后解析成 dom 树、解析 css 生成 css 规则树、合并成 render 树,然后 layout、painting 渲染、复合-`图层的合成、GPU 绘制、外链资源的处理、loaded 和 domcontentloaded 等)7.CSS 的可视化格式模型(元素的渲染规则,如包含块,控制框,BFC,IFC 等概念)8.JS 引擎解析过程(JS 的解释阶段,预处理阶段,执行阶段生成执行上下文,VO,作用域链、回收机制等等)9.其它(可以拓展不同的知识模块,如跨域,web 安全,hybrid 模式等等内容)
# 解析页面流程
1.解析 HTML,构建 DOM 树2.解析 CSS,生成 CSS 规则树3.合并 DOM 树和 CSS 规则,生成 render 树4.布局 render 树(Layout/reflow), 负责各元素尺寸、位置的计算5.绘制 render 树(paint),绘制页面像素信息6.浏览器会将各层的信息发送给 GPU,GPU 会将各层合成(composite),显示在屏幕上
# 渲染
- 计算 CSS 样式
- 构建渲染树
- 布局,主要定位坐标和大小,是否换行,各种 position overflow z-index 属性
- 绘制,将图像绘制出来
# Reflow 回流
当渲染树中的一部分(或全部)因为元素的规模尺寸,布局,隐藏等改变而需要重新构建, 这就称为回流(reflow)
- 页面渲染初始化
- DOM 结构改变,比如删除了某个节点
- render 树变化,比如减少了 padding
- 窗口 resize
- 获取某些属性,引发回流
offset(Top/Left/Width/Height)scroll(Top/Left/Width/Height)cilent(Top/Left/Width/Height)width, height- 调用了
getComputedStyle()或者 IE 的currentStyle
- 改变字体大小会引发回流
- 元素尺寸的改变——大小,外边距,边框
# 重绘(repaint 或 redraw)
重绘发生在元素的可见的外观被改变,但并没有影响到布局的时候。 例,仅修改 DOM 元素的字体颜色(只有 Repaint,因为不需要调整布局)
# 回流一定伴随着重绘,重绘却可以单独出现
# 回流重绘的优化方案
- 减少逐项更改样式,最好一次性更改 style,或者将样式定义为 class 并一次性更新
- 避免循环操作 dom,创建一个 documentFragment 或 div,在它上面应用所有 DOM 操作,最后再把它添加到 window.document
- 避免多次读取 offset 等属性。无法避免则将它们缓存到变量
- 将复杂的元素绝对定位或固定定位,使得它脱离文档流,否则回流代价会很高
# 引擎对 JS 的处理过程
1.读取代码,进行词法分析(Lexical analysis),然后将代码分解成词元(token)2.对词元进行语法分析(parsing),然后将代码整理成语法树(syntax tree)3.使用翻译器(translator),将代码转为字节码(bytecode)4.使用字节码解释器(bytecode interpreter),将字节码转为机器码
# 浏览器缓存
juejin/浅谈 HTTP 缓存 (opens new window)
- 强缓存
Expires: 值是服务器告诉浏览器的缓存过期时间
cache-control: 值是相对时间内直接使用浏览器缓存
2
- 协商缓存
Last-Modified 和 If-Modified-Since : 文件在服务器上最近的修改时间
Etag 和 If-None-Match : 只有当文件内容改变时,ETag才改变
2
- 缓存的优先级
Cache-Control > Expires > ETag > Last-Modified
# HTTP 常见状态码
200:表明该请求被成功地完成,所请求的资源发送回客户端201:表示请求成功且服务器创建了新的资源202:表示服务器已经接受了请求,但还未处理301:表示永久重定向,请求的网页已经永久移动到新位置302:表示临时重定向304:自从上次请求后,请求的网页未修改过,请客户端使用本地缓存400:客户端请求有错(譬如可以是安全模块拦截)401:服务器无法理解请求的格式402:请求未授权403:禁止访问404:资源未找到500:服务器内部错误503:服务不可用
# HTTPS通信(握手)过程
https://juejin.cn/post/6908327746473033741#heading-30
https采用非对称加密+对称加密,非对称加密来传递密钥;对称加密来加密内容
- 1.客户端向服务器发起请求,请求中包含使用的协议版本号、生成的一个随机数、以及客户端支持的加密方法
- 2.服务器端接收到请求后,确认双方使用的加密方法、并给出服务器的证书、以及一个服务器生成的随机数
- 3.客户端确认服务器证书有效后,生成一个新的随机数,并使用数字证书中的公钥,加密这个随机数,然后发给服 务器。并且还会提供一个前面所有内容的 hash 的值,用来供服务器检验
- 4.服务器使用自己的私钥,来解密客户端发送过来的随机数。并提供前面所有内容的 hash 值来供客户端检验
- 5.客户端和服务器端根据约定的加密方法使用前面的三个随机数,生成对话秘钥,以后的对话过程都使用这个秘钥来加密信息
# HTTP2
- 二进制协议:HTTP/2 是一个二进制协议。在 HTTP/1.1 版中,报文的头信息必须是文本(ASCII 编码),数据体可以是文本,也可以是二进制。HTTP/2 则是一个彻底的二进制协议,头信息和数据体都是二进制,并且统称为"帧",可以分为头信息帧和数据帧。 帧的概念是它实现多路复用的基础。
- 多路复用: HTTP/2 实现了多路复用,HTTP/2 仍然复用 TCP 连接,但是在一个连接里,客户端和服务器都可以同时发送多个请求或回应,而且不用按照顺序一一发送,这样就避免了"队头堵塞"【1】的问题。
- 数据流: HTTP/2 使用了数据流的概念,因为 HTTP/2 的数据包是不按顺序发送的,同一个连接里面连续的数据包,可能属于不同的请求。因此,必须要对数据包做标记,指出它属于哪个请求。HTTP/2 将每个请求或回应的所有数据包,称为一个数据流。每个数据流都有一个独一无二的编号。数据包发送时,都必须标记数据流 ID ,用来区分它属于哪个数据流。
- 头信息压缩: HTTP/2 实现了头信息压缩,由于 HTTP 1.1 协议不带状态,每次请求都必须附上所有信息。所以,请求的很多字段都是重复的,比如 Cookie 和 User Agent ,一模一样的内容,每次请求都必须附带,这会浪费很多带宽,也影响速度。HTTP/2 对这一点做了优化,引入了头信息压缩机制。一方面,头信息使用 gzip 或 compress 压缩后再发送;另一方面,客户端和服务器同时维护一张头信息表,所有字段都会存入这个表,生成一个索引号,以后就不发送同样字段了,只发送索引号,这样就能提高速度了。
- 服务器推送: HTTP/2 允许服务器未经请求,主动向客户端发送资源,这叫做服务器推送。使用服务器推送提前给客户端推送必要的资源,这样就可以相对减少一些延迟时间。这里需要注意的是 http2 下服务器主动推送的是静态资源,和 WebSocket 以及使用 SSE 等方式向客户端发送即时数据的推送是不同的。
# HTTP3
- HTTP/3基于UDP协议实现了类似于TCP的多路复用数据流、传输可靠性等功能,这套功能被称为QUIC协议
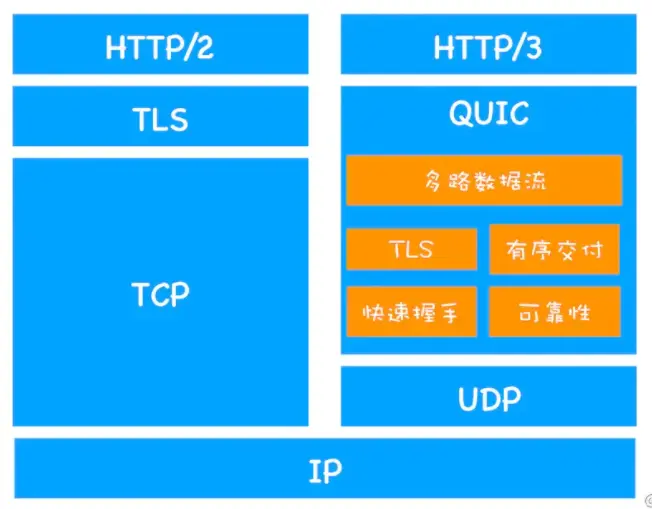
- 流量控制、传输可靠性功能:QUIC在UDP的基础上增加了一层来保证数据传输可靠性,它提供了数据包重传、拥塞控制、以及其他一些TCP中的特性。
- 集成TLS加密功能:目前QUIC使用TLS1.3,减少了握手所花费的RTT数。
- 多路复用:同一物理连接上可以有多个独立的逻辑数据流,实现了数据流的单独传输,解决了TCP的队头阻塞问题
- 快速握手:由于基于UDP,可以实现使用0 ~ 1个RTT来建立连接
# Cache-Control: no-cache 和no-store的区别
Cache-Control: no-store:这个才是响应不被缓存的意思 Cache-Control: no-cache是会被缓存的,只不过浏览器每次都会向服务器发起请求,来验证当前缓存的有效性
# 垃圾回收机制
原文 https://juejin.cn/post/7146996646394462239
# GC 垃圾回收策略
- 标记清除
分为 标记 和 清除 两个阶段,标记阶段即为所有活动对象做上标记,清除阶段则把没有标记(也就是非活动对象)销毁 在运行时会给内存中的所有变量都加上一个标记,假设内存中所有对象都是垃圾,全标记为0 然后从各个根对象开始遍历,把不是垃圾的节点改成1,清理所有标记为0的垃圾,销毁并回收它们所占用的内存空间。最后,把所有内存中对象标记修改为0,等待下一轮垃圾回收
- 引用计数
一个对象,如果没有其他对象引用到它,这个对象就是零引用,将被垃圾回收机制回收 它的策略是跟踪记录每个变量值被使用的次数 一个对象被其他对象引用时,这个对象的引用次数就为 1,如果同一个值又被赋给另一个变量,那么引用数加 1,如果该变量的值被其他的值覆盖了,则引用次数减 1 当这个值的引用次数变为 0 的时候,说明没有变量在使用,这个值没法被访问了,回收空间,垃圾回收器会在运行的时候清理掉引用次数为 0 的值占用的内存
# 分代式垃圾回收机制
V8采用了一种代回收的策略,将内存分为两个生代:新生代和老生代 新生代中的对象为存活时间较短的对象,老生代中的对象为存活时间较长或常驻内存的对象